iTagPDF: Towards Finally Automating PDF Accessibility
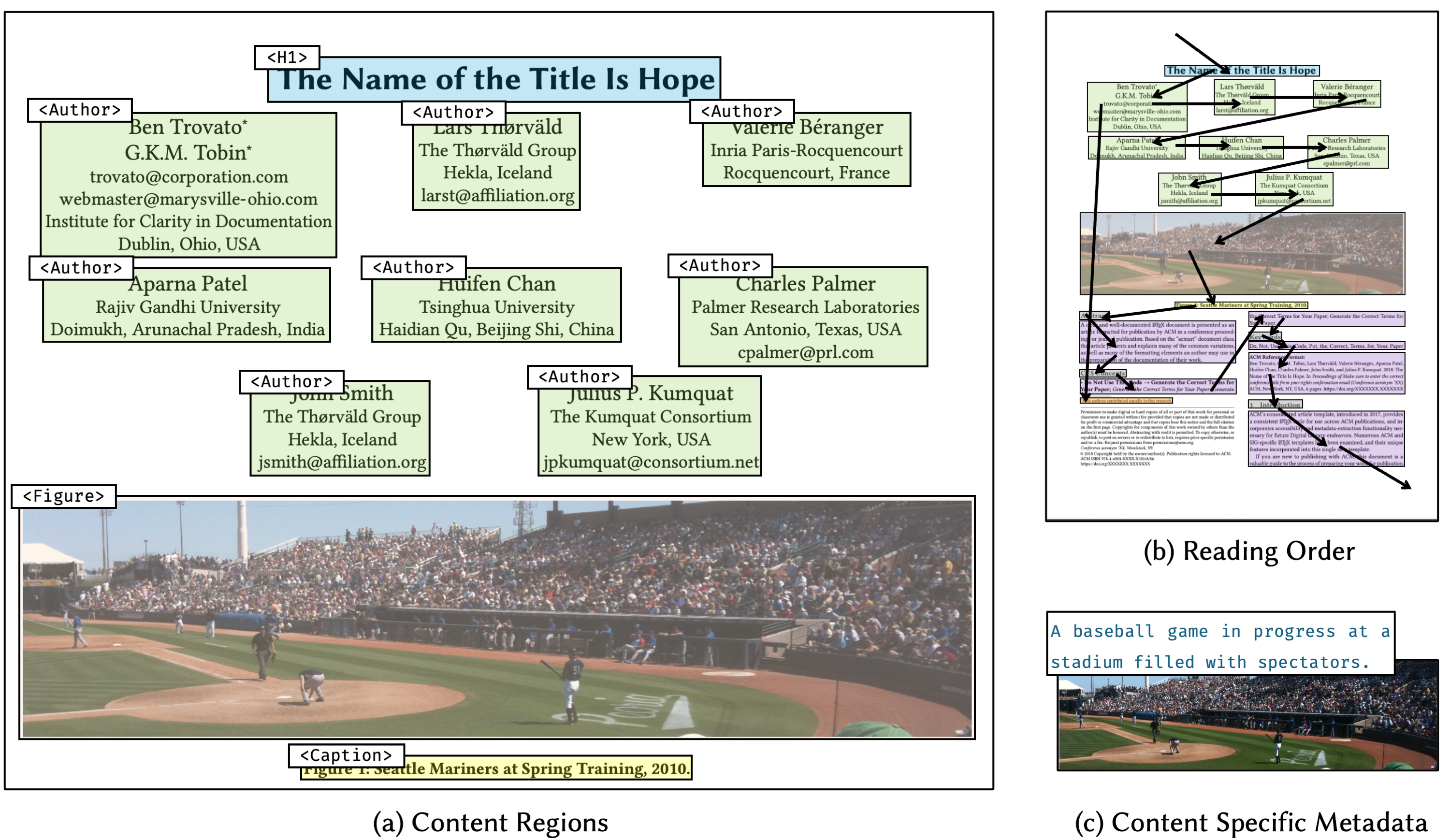
Intelligent PDF Tagging (iTagPDF) automatically produces three kinds of PDF accessibility metadata: (a) content regions and their locations (tags), (b) their reading order, and (c) content specific metadata, such as structure information for tables and alt texts for figures and formulas. iTagPDF is the first to combine all major tasks of making a PDF accessible into one tool, and outperforms all prior approaches by jointly modeling the input source and the rendered pixels of the PDF.
@inproceedings{10.1145/3772318.3790289,
author = {Mowar, Peya and Steinfeld, Aaron and Bigham, Jeffrey P},
title = {iTagPDF: Towards Finally Automating PDF Accessibility},
year = {2026},
isbn = {9798400722783},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3772318.3790289},
doi = {10.1145/3772318.3790289},
booktitle = {Proceedings of the 2026 CHI Conference on Human Factors in Computing Systems},
articleno = {1116},
numpages = {17},
location = {Barcelona, Spain},
series = {CHI '26}
}